翻译了国外一个大神的WP,我什么时候能有这么强😭
原文链接:GoogleCTF2022 - eldar
复现强网杯的deeprev的时候知道的这题,本文是照着复现,翻译了一部分,部分名词我会标注英文原文。很多地方翻的很别扭,因为本人的英语水平实在是太🌶️🐔了……
墙裂建议阅读原文 不然看我写的可能只会收获一头雾水。
其实感觉还是搞得不是很明白,以后如果顿悟了再过来补充(x
涉及到的技术:
“Weird Machines” in ELF: A Spotlight on the Underappreciated Metadata
Programming Weird Machines with ELF Metadata
ELF重定位
ELF动态重定位的结构如下:
1 | typedef struct { |
info包括一个type和symble(可选)索引:
1 |
动态符号表也是相关的,结构如下:
1 | typedef struct { |
所有重定位信息都写入r_offset指向的地址。写入的值取决于重定位类型。
eldar使用了以下4种重定位信息:
REL (type 8)
将重定位信息设置为一个相对基址的值(但是基址始终为0)
1 | *(uint64_t *)r.r_offset = r.r_addend; |
R64(type 1)
将重定位信息设置为 符号值+常数 (原文中是addend)
1 | *(uint64_t *)r.r_offset = symbols[ELF64_R_SYM(r.r_info)] + r.r_addend; |
R32 (type 10)
和R64一样,只不过被截断为32位。
1 | *(uint32_t *)r.r_offset = symbols[ELF64_R_SYM(r.r_info)].st_value + r.r_addend; |
CPY(type 5)
从符号地址复制n字节到重定位地址
1 | Elf64_Sym sym = symbols[ELF64_R_SYM(r.r_info)]; |
Part1 解析
我发现lief解析重定位数据和符号信息非常方便
1 | import lief |
结果:
1 | ... |
10w多行重定位信息对于人类来说还是太抽象了 (这句话是我写的
这时我注意到了一些奇怪的重定位信息:[0377] :: r64 0, 6 + 0
这是往一个空指针里写东西,但是程序没🐔,所以可能是一些重定位信息在执行时会被修改。
我们可以检查数字落在哪个范围内,如果它位于.rela.dyn或.dynsym部分内,则为其分配一个符号值,而不是使用原始数字。我们也知道flag(serial符号)在[0x404040:0x40405d],fail在0x404060。
定义我们的符号值:
1 |
|
然后再写一个函数format_addr把虚拟地址转为符号值:
1 | rela = [x for x in b.sections if x.name == '.rela.dyn'][0] |
解析时,对每一个数值先调用函数format_addr(此处未展示)。可以得到以下内容:
1 | // Interesting section of NOPs: |
我们还能看到类似的东西:
1 | [0349] :: copy r350.r_addend, s2 |
349覆写了350中的加数。实际上,这两句话应该是s4 += s2(0被覆写为s2)
下面也有相似的覆写地址的操作:
1 | [0376] :: copy r377.r_address, s2 |
如果我们对这些结构进行模式匹配并定义更高级别的操作,我们可能会得到一些更简洁的代码
Part2
不要问我为什么不翻译标题,因为这句话我也没看懂!😭(如果有知道是什么意思的师傅请务必告诉我
Arr + Out references
在解析过程中,我注意到一些重定位信息被作为NOP使用(向固定地址写入0)。其他重定位信息也会向那些重定位点(如一个uint64_t数组)写入任意的值。
特别指出,r3到r88似乎被用作一个数组。r89似乎是某种输出值(之后会说)。
我们可以修改format_addr来理解这些引用:
1 |
|
样例1(102000条指令)
1 | // Nice array references! |
好看多了!
Mov + Add
下一步我们可以把Rel,R64和Copy使用更容易理解的Mov和Add替换
为了知道mov的大小(根据Copy变化),我们需要追踪所有指令,然后跟踪每个偏移处的符号大小。我们可以只看向符号st_size写的部分来观察这些变化。幸运的是,它们在这个程序里是确定的。
1 | Mov = namedtuple('mov', ['dst', 'src', 'sz', 'ridx']) |
我们还需要更新我们的dump函数以支持这些新类型:
1 | def dump(instructions): |
示例2(96179条指令)
1 | // smoooth |
间接mov
前面提到过,某些重定位里的r_addend会在用到之前被修改。举个🌰:
1 | [0349] :: mov r350.r_addend, s2 |
这3句指令其实就是s4 = s2。我感觉产生第3条指令是程序编译方式的问题,这玩意其实应该没什么用。
用python3.10来match,我们可以对这种类型的结构执行清晰的模式匹配,并用一条Add指令替换它:
1 | def lift_indirect(instructions): |
样例3 (58155条指令)
1 | [0346] :: mov s4, &0 |
分块
检查汇编代码,我们可以发现重复的代码块:
1 | // --------------- |
这些块干的事情就是:
1 | # --- |
似乎只有arr和flag的索引改变了。改一下
1 | Block = namedtuple('block', ['arr', 'flag', 'ridx']) |
样例4(23339条指令)
1 | // array set |
重置(Reset)和块移动(ShuffleBlock)
(这里的重置就是清零的意思,块移动看看样例就懂了(雾)
很多指令是用于数组初始化的,我们可以把它们淦掉(雾
还可以淦掉很多用于移动的指令(lift和shuffle不知道怎么翻译了,不过看了样例就知道什么意思了
1 | Reset = namedtuple('reset', ['ridx']) |
样例5(19259条指令)
1 | [0090] :: reset // wow |
Output
在每个reset/shuffleblock对之间,似乎有三个重复的指令块写入该out区域:
1 | // --------------- |
它们干的事情就是:
1 | # --- |
我们把它淦掉:
1 | Output = namedtuple('output', ['out', 'arr', 'ridx']) |
样例6(18659条指令)
1 | // hey this is looking almost readable |
MultAdd
(就是多次加法)
check到flag[16]之后,上面那种代码没了,换了新的加密方式。
遇到一些新的块,它们似乎不太一样:
1 | / ---------- |
这些块干的事情就是:
1 | // s5 = out[3] |
内部的一些代码执行的就是s6 += s5(+)或s6 += s6(×2)
举个🌰:
1 | [64730] :: mov s2, &out[2] |
虽然有点麻烦,但我们还是可以把它淦掉:
1 | MultAdd = namedtuple('multadd', ['out', 'val', 'k', 'ridx']) |
样例7(2377条指令)
1 | [56795] :: mov s4, &0 |
Trunc
每组madd指令之后,我们看到一些奇怪的指令:
1 | [65888] :: mov s2, &s5.11 |
我们正在往一个符号值的偏移为11的地方(就是&sym.st_value + 3)写入值。
检查这些代码,可以发现s5总为0。所以这个指令就是把这个符号值的高5字节清零,即sym &= 0xffffff
1 | Trunc = namedtuple('trunc', ['val', 'k', 'ridx']) |
样例8(2336条指令)
1 | [80967] :: madd s7 += (&out[17] * 219) |
Array slots
在新的字节码里,我们发现了巨多常量。还有一些像数组的新地方:
注意:setinfo只是一个进入st_name设置其他字段的8字节mov。
1 | // NOP relocations for array space |
这些数组似乎总是由一堆nop指令(mov baseaddr(), &0)组成,后面跟着一堆mov来给数组赋值。
我们可以扫描这种字节码并放到一个固定的常量数组中:
1 | ArraySlots = namedtuple('arr', ['values', 'ridx']) |
样例9(2161条指令)
1 | [93677] :: mov s5, &0 |
Shellcode
现在问题是那些值是啥东西?我刚开始以为它们是某些矩阵算出来的值。
但是我注意到0x48前缀和0xc3后缀,并对字节码产生了怀疑。我之前还注意到,重新定位部分被标记了rwx。
所以让我们把第一个块扔进 Binary Ninja,看看会发生什么……
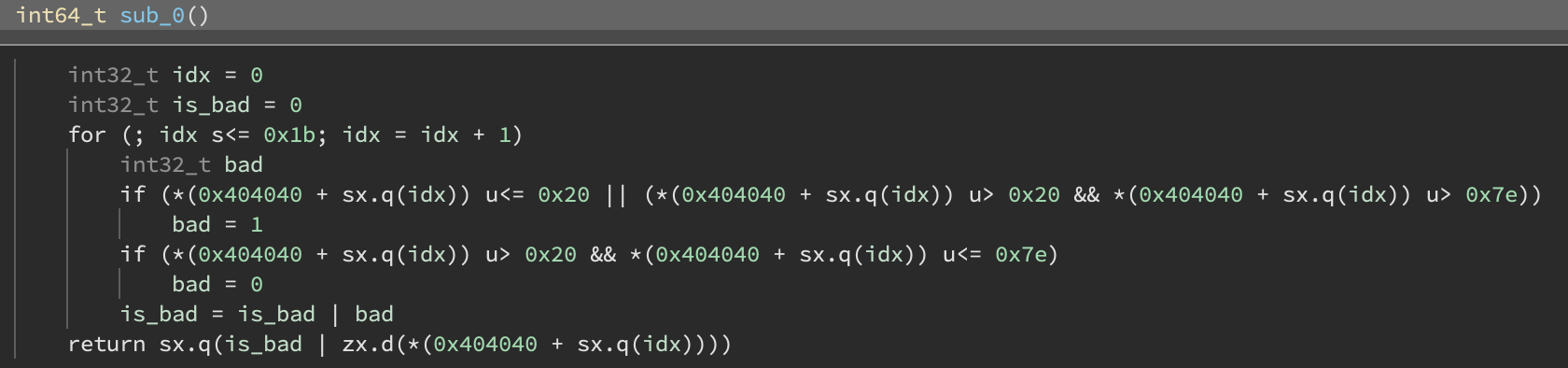
彳亍,那肯定是字节码了。第一个大函数似乎只是检查所有标志字节是否在(0x20, 0x7e)范围内。
这也是唯一的大功能,其余的似乎都是9字节的shellcode数据。
我不太了解shellcode 是如何在这里实际执行的,但它与加载指向 shellcode 的符号有关。我们可以将以下块识别为“执行 shellcode”块:
1 | [93806] :: array [-0x60ff7fbf1bdadb80, 0xc3, 0x0] |
把它淦掉:
1 | from capstone import * |
dump的时候可以通过capstone得到漂亮的反汇编代码:
1 | def dump(instructions): |
样例10(1771条指令)
1 | // have you seen sexier disassembly? |
Aop
所以这个shellcode只是被用来做更多类型的操作的一种机制。
举个🌰:
1 | [100512] :: mov s2, &flag[19] |
这个块就是s7 += (flag[19] >> 3)
我们可以定义一个类似于madd的aop(加操作),不过它多了一个操作符号:
1 | Aop = namedtuple('aop', ['dst', 'op', 'val', 'k', 'ridx']) |
样例11(1147条指令):
1 | // out madd computation |
跟着走下来突然感觉1k条指令已经算少的了🤣
怪不得av神曾曰:“区区几千个函数”
被分成了这样的块:
1 | [98963] :: mov s7, &-80711 |
接近结尾的时候可以看到:
1 | [101625] :: mov fail(), &0 |
所以s4必须保持0,否则就设置fail符号,说明flag是错误的。
所以上面的块表示对部分flag的操作,然后再加上-80711(s7里)必须等于0
后半段flag
flag[16:27]约束一下,z3一把梭了:
1 | from z3 import * |
output数组
我用z3去约束out数组(这数组里只用了madd),但是8太彳亍。
ctfer宁愿用z3解线性方程组,也不愿学习矩阵是个啥。
— cts (@gf_256) July 2, 2022
每个单独的约束只有madd,相当于矩阵里的一行,因为正好有24个out值和24组约束(是个方阵),所以我们可以求解这个矩阵。
这次不用z3,用np.linalg.solve来求解矩阵:
1 | import numpy as np |
前半段flag
这个out数组是根据flag的前16个字节和这些块计算的:
1 | [0347] :: shuffleblock &flag[0], &flag[1] |
具体来说,out[0:3]由flag[0:2]计算得到。out[3:6]由flag[2:4]得到,以此类推。
对于每个3元组可以直接爆破:
1 | def solve_start_flag(output): |
完结撒花
完整脚本:https://gist.github.com/hgarrereyn/9e536e8b3471d3cb8ecbb5932a776b95
关于本文
本文作者 云之君, 许可由 CC BY-NC 4.0.