再摸鱼要被制裁了……
*CTF 2022
simplefs
复现感觉也8难,为什么比赛的时候脑子就跟被糊了一样……
实际上instruction.txt已经给出提示了,但是我当时没太理解这是什么意思,所以直接忽略了,导致一直在错误的方向被折磨……
1 | # instructions |
出题人给出了运行参数和初始化的操作,然后再plantflag就能调进去主要逻辑。
1 | __int64 __fastcall enc(__int64 a1, int a2) |
程序运行参数设置为imagetest.flag 500,IDA远程去调。
我直接断在这个函数进不去,在外面有几句判断的跳转,把外面三句跳转全nop掉,然后成功了……调出来v4的值是0xDEEDBEEF,然后从低到高依次取1字节来循环移位和异或。
把*CTF按这个逻辑加密一下,出来的密文是0,0xd2,0xfc,0xd8,在imagetest.flag里匹配一下这几个值,找到密文在偏移0x49000处,然后写脚本复原一下就可以了。因为懒得写解密就直接用原来的加密程序的屑……
1 | import binascii |
Jump
setjump和longjump
非局部跳转语句: 在栈上跳过若干调用帧,返回到当前函数调用路径上的某一个函数中。
与goto语句不同,setjmp允许跨函数调用,但是goto不允许。
int setjmp(jmp_buf env);:从longjmp调用返回longjump的val值,直接调用返回0。void longjmp(jmp_buf env,int val);:返回到setjmp,其中env是setjmp的env,val是setjmp的返回值。
使用第二个参数的原因是一个setjump可以有多个longjmp。
setjmp被调用时,其jmp_buf结构的内存应该未被释放。
感觉好像跟异常处理那个很像,可以直接跳过栈帧🐏了所有局部变量
主函数:
1 | int __cdecl main(int argc, const char **argv, const char **envp) |
首先是gets,然后是一堆抽象的setjump和longjmp,能看的函数就sub_402689、sub_401F62和sub_402826
sub_402689:
1 | void __noreturn sub_402689() |
给输入前面加2后面加3然后sprintf到qword_4C9400,后面的if把qword_4C9400层层移位放到qword_4C9660指向的一堆数组里形成一个矩阵。
sub_401F62是一坨又臭又长的函数……不过是对矩阵做操作,可以先动调跳过,观察前后数据来推测一下函数行为。
执行sub_401F62后,使用一个IDAPython脚本来打印出qword_4C9660指向的矩阵:
1 | addr = [0x8530F0,0x853720,0x853120,0x853150,0x853180,0x8531B0,0x8531E0,0x853210,0x853240,0x853270,0x8532A0,0x8532D0,0x8534E0,0x8536F0,0x853540,0x853360,0x853570,0x8535A0,0x8535D0,0x853450,0x853600,0x853630,0x853660,0x853480,0x8534B0,0x853300,0x853390,0x853510,0x8533C0,0x853420,0x853330,0x8536C0,0x8533F0,0x853690,0x853750] |
我的输入是0123456789qwertyuiopasdfghjklzxc,打印结果:
1 | b'\x020123456789qwertyuiopasdfghjklzxc\x03' |
可以观察到是按照每个字符串的第一个字符(字典序)来排序。
sub_402826:
1 | void __fastcall __noreturn sub_402826(__int64 a1, __int64 a2, __int64 a3, __int64 a4, __int64 a5, __int64 a6) |
取了矩阵的每一列的最后一个字符存到byte_4C9420,然后跟密文比较。
那么现在获取到的密文就是矩阵最后一列,排序之后的密文就是矩阵第一列。
这两列密文索引值相同的字符一定是挨着的,因为最初是层层移位的。
现在已知flag第一个字符一定是\x02(程序里加的),那么就依次去最后一列找当前字符的索引值,索引到第一列字符,就是当前的flag字符。
比如第0位字符是\x02,那么就去最后一列找\x02的索引值,然后第一列相应的这个字符就是挨着\x02的字符(即第1位字符),以此类推。
1 | enc = [0x03, 0x6A, 0x6D, 0x47, 0x6E, 0x5F, 0x3D, 0x75, 0x61, 0x53, |
不知道为什么有时候调到longjump会直接退出程序 = =
太玄学了,调得想砸电脑
NaCl
氯化钠氯化钠!
比赛的时候 一直想着氯化钠 没看这题,因为在我的WSL1上直接segment fault了 = =
不过今日我早已换了WSL2!它成功运行了!!!来试试!(兴奋地搓搓手
新技能get:IDA trace来逝一逝
断点下在加密函数,断下之后开始trace,然后走完一轮加密,把trace全部copy出来分析。
(我的输入:01234567890123456789012345
有加密的话直接去找cmp,用循环的话肯定会用到这个指令,然后就可以把代码段分成一段一段的循环,这样方便理解逻辑。
可以对比着动态调试去理解,需要的数据直接去栈上抄。

然后做苦力嗯分析就好了
1 | 0000004F SFI:sub_80807C0+E5 jle loc_80807E0 |
后面xxtea就不贴了,手搓解密脚本即可。
解密脚本不贴了,因为刚开始出了点问题,后来跟zsky学长的脚本一一对比,到最后已经基本上是逐句复制粘贴………………
那么所以某个傻子的脚本到底是哪里出了问题呢?
其实就是这一句v[1] = rol(v[0],2) ^ (rol(v[0],8) & rol(v[0],1)) ^ tmp ^ key[43 - k];
rol的定义我是这样写的:#define rol(w,r) (w<<r)|(w>>(32-r)
宏定义一定要带括号!!!
宏定义一定要带括号!!!
宏定义一定要带括号!!!
这样是不是好像没什么问题?但是不像函数一样是返回一个值,宏定义是不管这些直接替换的,所以说rol这玩意被替换掉之后是不带括号的,而或运算的优先级很低,会被&和^抢占,这样解密就会出问题………………
你是怎么发现的?
关于我是怎么发现的………………因为XXTEA解密都是祖传脚本,那么出问题的只有可能是这里的代码了。
我试着调换了一下异或的顺序,它的结果居然改变了!!!
好吧,这铁运算优先级的锅了……就因为这个sb错误又浪费好久😭😭😭
或者PZ师傅那个思路也挺好的嗯,我只是想试一试trace
ACTF2022
dropper
UPX脱壳不能运行……就脱壳静态看,带壳动态调。这题还是有点邪门的,把ALSR扬了之后居然不能跑,估计是有校验什么的……那就带着调吧,反正影响不大。
主逻辑在sub_140019470,sub_1400113D9有一个异或,还原出傀儡进程的代码。
静态看找了半天没看到还原前的数据在哪,就直接上手调了(别问我为什么用IDA调,因为我是懒🐶
带壳程序载入IDA,有代码的地方翻到最底下,有个大跳jmp near ptr byte_140011591,在这下断然后直接跑,jmp之后就直接进入OEP了。
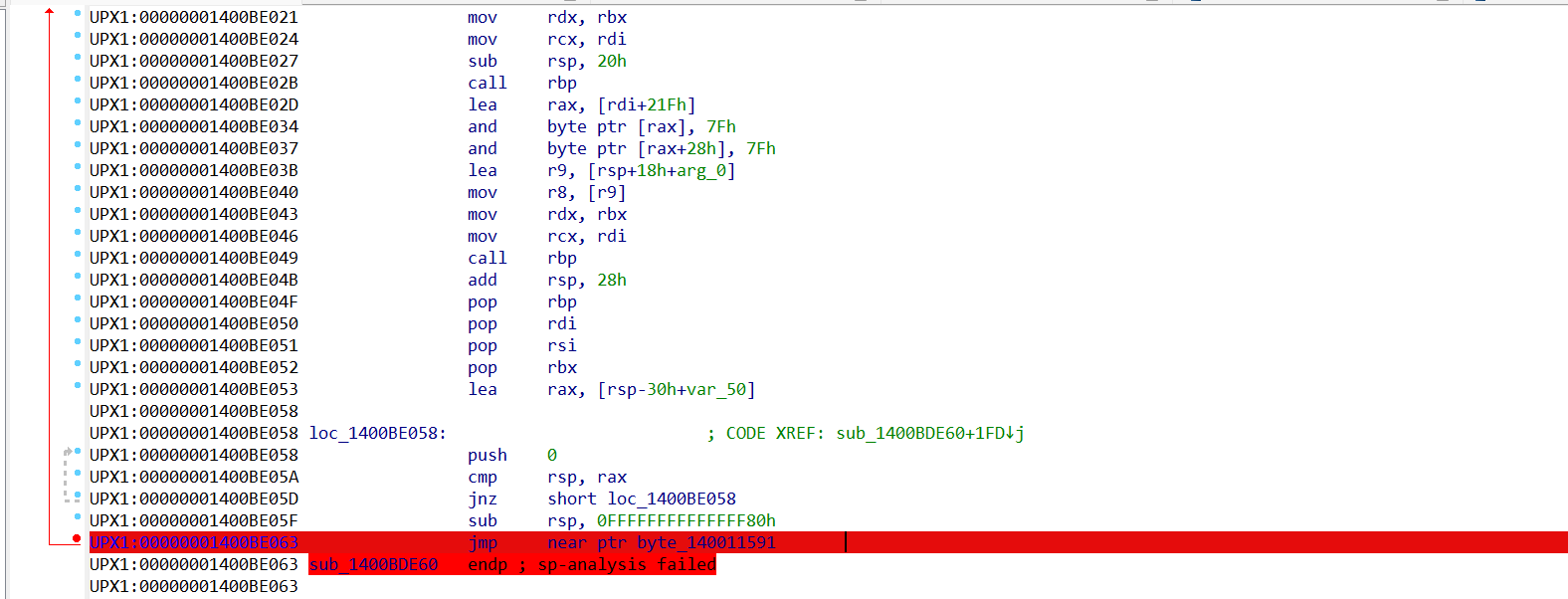
然后就对比着静态的函数逻辑,走到sub_1400113D9,看参数就能找到数据,然后使用IDAPython脚本dump数据:
1 | import idaapi |
异或还原:
1 | r = open("D:\\ctf\\tmp\\data.txt",'rb') |
别问我为什么不直接提取异或之后的数据……调了两次跑飞了,eip跳来跳去单步也步不动,不知道是什么bug🥲,搞得烦了直接抓瞎dump数据。
代码很长就不全部贴了,只贴关键部分 C++出题真不是人啊……
sub_7FF6E770D080:
1 | sub_7FF6E7701032(std::cin, (__int64)input);//输入 |
有用的是sub_7FF6E7701244,进去之后到sub_7FF6E770BC50,其中主要的一个循环:
1 | for ( v10[0] = 0; ; ++v10[0] ) |
pow1_3_to_2自己梳理一一下逻辑就会发现是个pow函数。这个for循环做的事情大概就是
1 | num = 128 #0x80 |
sub_7FF6E7701433转换了程序里的一组字符串,逆序4个一组(也就是万进制)去存。
sub_7FF6E7701226触发一个除零异常(7FF6E770C09F),触发异常后跳转到7FF6E770C0B9,替换虚表,把加密函数替换成sub_7FF6E770187F。此函数里就是做了一些加减乘的操作。
虽然逻辑不难,但是真的调到自闭啊啊啊啊啊啊啊啊啊啊啊这代码是真的难看啊嵌的一套又一套……
不知道为什么我把异常pass to application之后就直接异常退出了,不会转到异常处理……又是每天一个玄学问题
1 | box = [8433, 7593, 342, 2871, 1984, 1642, 9440, 3394, 8311, 2028, 7079, 8305, 248, 657, 986, 5500, 7924, 9497, 3109, 8290, 8787, 1600, 2271, 7732, 8512, 3986, 923, 4719, 9219, 3685, 496, 6248, 365, 1718, 8724, 5635, 6437, 5806, 4816, 6193, 396, 3063, 3735, 206, 1564, 912, 6633, 8869, 5633, 6686, 5073, 3516, 4477, 8799, 8818, 123, 9190, 1695, 723, 7151, 998, 6100, 8836, 952, 593, 5702, 374, 2078, 9411, 7813, 4247, 4708, 2612, 6715, 4071, 9894, 8003, 6194, 8622, 572, 1218, 9605, 6119, 5597, 9744, 7046, 3370, 1814, 7205, 8345] |
关于本文
本文作者 云之君, 许可由 CC BY-NC 4.0.